在網站可靠性工程(SRE, Site Reliability Engineering)中,常常會聽到 SLI / SLO / SLA 這三個名詞。
它們看起來相似,但在 SRE 中各自有清楚且不同的定位。
本文將先從最基礎、也最重要的 SLI(Service Level Indicator) 開始,說明可靠性工程是如何被量化與觀測的。
SLI (Service Level Indicator)的定義
SLI = 服務層級指標
它是一組 可以量化的數據,用來衡量系統目前的健康狀態或服務品質。
換句話說,SLI 就是「我們要監控什麼數字,來判斷服務好不好」。
常見的 SLI 指標
常見也最實用的 SLI:
- 延遲 (Latency)
- 請求處理時間,例如:p95 Latency < 500ms
- 用來衡量使用者感受到的「快或慢」
- 錯誤率 (Error Rate)
- 錯誤請求數 / 總請求數
- 用來快速判斷服務是否出現異常。
- 可用性 (Availability)
- 成功請求 / 總請求
- 例如:99.9% availability
- 吞吐量 (Throughput)
- 每秒請求數 (QPS) 或每分鐘交易數
- 用來看系統能否應付高峰流量
實作範例:Cloud Run + Cloud Monitoring(SLI Dashboard)
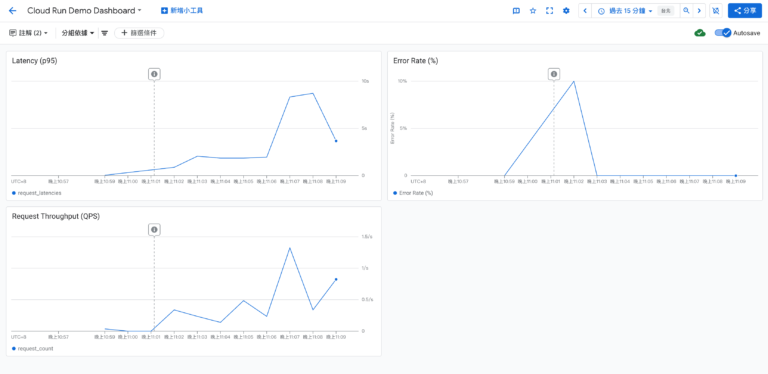
以我最近的 Demo 為例,我在 GCP Cloud Run 部署了一個服務,並用 Cloud Monitoring 建立了三個 SLI
指標,嘗試練習設定 指標的設計以及觀測的方式。
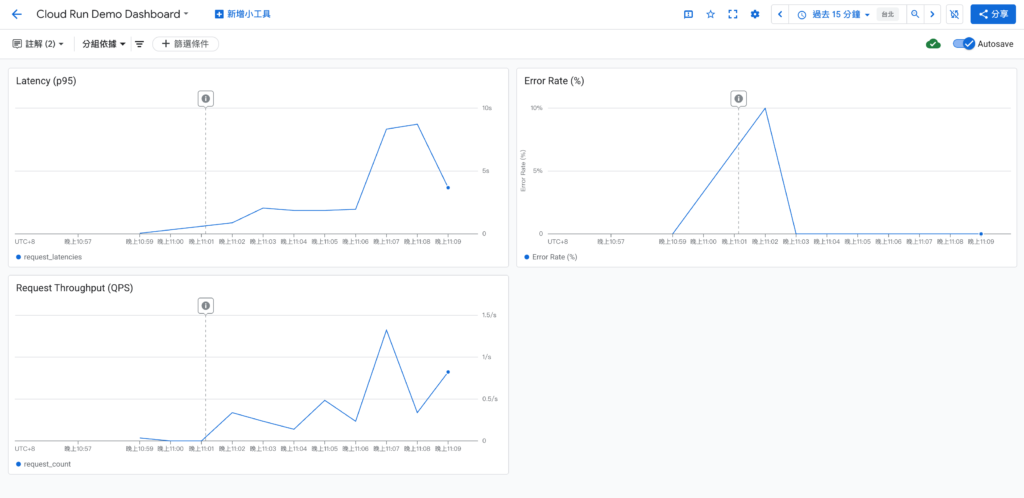
- 左上 - Latency (p95)
追蹤 95% 請求的回應時間,用來判斷使用者是否感覺服務變慢
(這個網站應用程式都是使用免費的方案,所以很慢) - 右上 - Error Rate (%)
計算 5xx 錯誤請求數 / 總請求數
(因 Cloud Run 最小實例數設為 0,冷啟動期間曾短暫出現 5xx 錯誤) - 左下 - Request Throughput (QPS)
每秒請求數,用來觀察流量變化
(在後段刻意產生較多請求時,可觀察延遲隨流量上升)
這三張圖表放在同一個 Dashboard,就能快速回答:
- 使用者是不是覺得慢?(Latency)
- 系統是不是掛了?(Error Rate)
- 流量是不是暴增?(Throughput)
為什麼 SLI 很重要?
因為 沒有數字,就沒有可靠性。
SRE 的核心不是「憑感覺」判斷系統健康,而是用 SLI 這些可量化的數據,建立可靠的決策依據。
SLI 定義好之後,我們才能進一步設定 SLO (目標),最後再延伸到 SLA (客戶承諾)。
SLO(Service Level Objective)
SLO 可以當作替剛剛的 SLI 畫出的一條「合格線」,而且必須同時包含:
- 指標定義(SLI)
- 門檻條件(例如 latency < 200ms、status < 500)
- 目標比例(99%、95%)
- 評估時間窗(Rolling period / Calendar period,如 7 天、30 天、90 天)
設定 SLO 時,通常會依序進行:
- 定義什麼是「好請求 / 壞請求」
- 設定門檻條件
- 設定目標比例與時間窗
在 Google Cloud Monitoring 中,第一步會先選擇 SLI 類型,用來決定如何判斷請求的好壞。
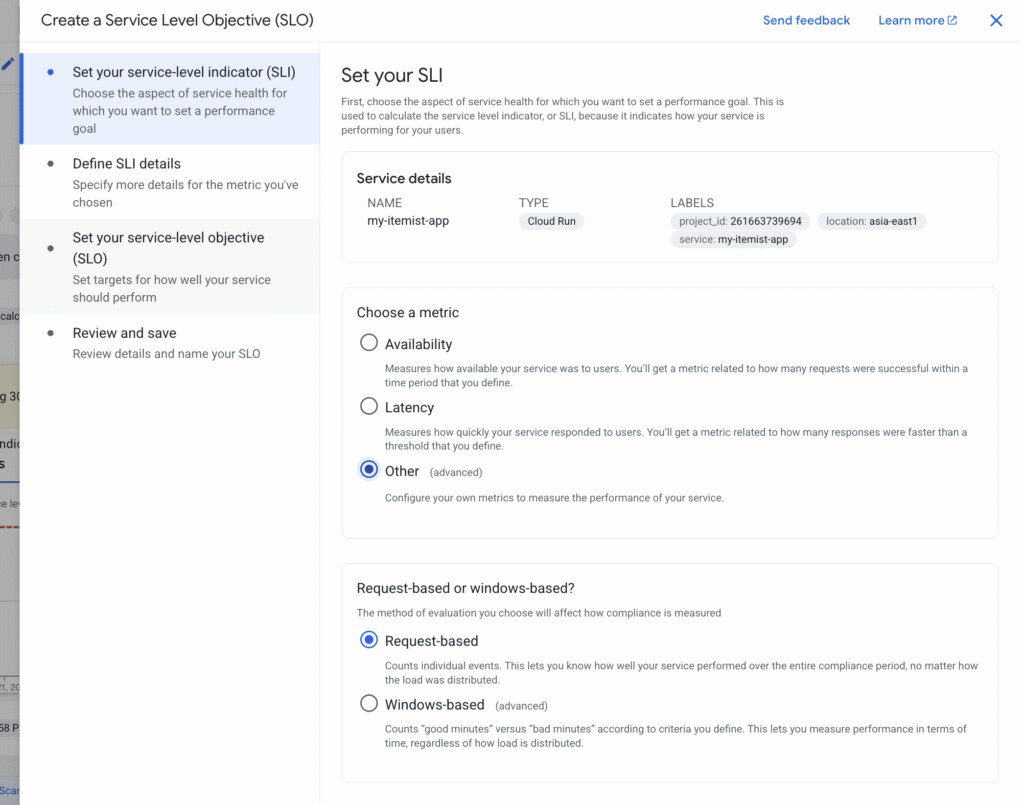
- Availability
- 用成功請求 / 總請求次數。
- 適合 API、Web 服務,代表「服務有沒有回應」。
- 例如:我要 99% 的 API request 都能成功回覆。
- Latency
- 衡量「多少比例的請求低於某個延遲門檻」。
- 適合對反應速度要求高的服務。
- 例如:95% 的請求要在 200ms 內完成。
- Other (advanced)
- 自定義 SLI。
- 可以把應用程式的 自定義 metrics(例如:上傳圖片成功率、特定 API 的錯誤比例)丟進 Cloud Monitoring,再用這裡來建。
- 比較進階,適合之後要做產品特定的可靠性指標。
SLA(Service Level Agreement)
SLA 是將 SLO 寫進對外合約,並附帶後果的承諾。
- SLO:內部工程與營運目標
- SLA:對使用者的正式承諾
例如:「本服務保證 99% uptime,若未達成,將退還 10% 服務費用。」
總結
在學習 SRE 的過程中,我發現「可靠性」並不是什麼抽象概念,而是從一些可以被量化的指標開始慢慢建立起來的。
SLI 是實際用來觀測系統狀態的數字,SLO 則是在這些數字之上,替系統畫出一條「大致可接受的範圍」,而 SLA 則是把這些目標正式寫成對外的承諾。
對我來說,先把 SLI 定義清楚,是理解 SRE 非常重要的一步。因為只有當指標明確,後續在可靠性與開發速度之間的取捨,才有討論的基礎。
這篇文章主要是整理我目前對 SLI / SLO / SLA 的理解,之後也會再繼續記錄學習 SRE 過程中的一些心得。
